7 Lab 7. Levels of Processing: All Rehearsal is not the Same
COGLAB Exercise 29
Levels of Processing
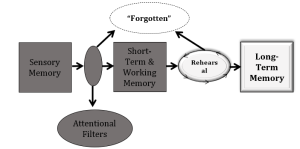
As we have seen, one of the most successful models of memory was the one proposed by Atkinson and Shiffrin (1968). In fact, this entire lab manual is organized around the three-store model proposed by them. As we have seen, this model is not without its weaknesses. Over the years, many researchers have identified a number of shortcomings of Atkinson and Shiffrin’s8 model. Even so, its simplicity (and frankly, its success at explaining a number of phenomena) has allowed this model to remain one of the most influential in cognition.
One of the simplifying assumptions of the Atkinson and Shiffrin model is that the likelihood of information being retained in LTM is a function of the amount of time that information is rehearsed in STM. That is, items that are rehearsed more often have a greater likelihood of being transferred to LTM. The explanation of the primacy effect in Lab 6 draws on this assumption. Items at the beginning of the list are better recalled because they spend more time (and with less competition) than items from the middle or end of the list.
Although this was recognized as a simplifying assumption of Atkinson and Shiffrin,–meaning it wasn’t adopted because it was thought to be correct, necessarily, but because the model focused on other aspects of memory–it quickly drew significant criticism. You have undoubtedly proven this fallacy yourself: if you have even spent a great deal of time rehearsing information for a test using rote memorization, you’ve probably found it to be terribly inefficient (and not terribly effective, either). Amount of rehearsal time is certainly important, but the kind of rehearsal is important as well. In other words, the quality of rehearsal may be more important than the quantity of rehearsal.
Craik and Lockhart (1972) proposed an alternative to the Atkinson and Shiffrin model that has been come to be known as the levels of processing model. Craik and Lockhart distinguished between two kinds of rehearsal: maintenance rehearsal, or simple rote repetition, and elaborative rehearsal, which involves dealing with the meaning of what you are studying. Maintenance rehearsal is what you use when you get a phone number from information, and wish to retain it only long enough to make one phone call. You may say the number to yourself over and over again, keeping the information active in your STM. Once you dial the number, it’s quickly lost from memory. This can be a problem if the number is busy, or if you are briefly distracted before you get a chance to dial. This is maintenance rehearsal, and regardless of how long you keep saying the number to yourself, it’s not likely to lead to a durable LTM.
On the other hand, if you are trying to learn a phone number that you will use repeatedly, you will likely make an attempt to relate that information to other items already in your memory. This illustrates elaborative rehearsal. One technique many people use is to convert a phone number into “years,” and then using events that transpired during those years as retrieval cues. The phone number for the Department of Psychology and Neuroscience at Baylor is (254) 710-2961. How could these numbers be encoded meaningfully? Most students know that “254” is the area code for Waco, and that almost all university phone numbers have the prefix “710.” What about the final digits? “29” could be encoded as “1929,” which is the year of the Stock Market crash, and the beginning of the Great Depression. By the time students reach college, hopefully, this is a part of their semantic memory. The digits “61” might be more difficult, but a real baseball fan can tell you what “61” means: when Babe Ruth’s record for home runs in a single season was broken by Roger Maris, Maris hit 61 homers—and he did it in 196114. Even if you are not a baseball fan you can probably use this to aid encoding of the information. The departmental telephone number, then, becomes: “Waco area code, Baylor prefix, Stock Market Crash, Roger Maris’s home runs.”
Does the quality of the rehearsal affect likelihood of transferring information to LTM? In a more detailed follow-up to the original Craik and Lockhart (1972), Craik and Tulving (1975)tested this by asking people to do one of three different things while reading a list of words. Some were asked to look at the physical features of the words in front of them. For example, they might be asked if a word was presented in ALL CAPITAL letters. Others might be asked to attend to the sound of the word; they might be asked if they word they were seeing rhymed with the word “block.” Others were asked to attend to the meaning of the word: they might be asked, does the word fit in the sentence, “The child played with the _____”. These conditions are summarized in Table 7.1
|
Level of Processing |
Task |
Example |
|
Shallow |
Is the word written in all capital letters? |
TREE |
|
Medium |
Does the word rhyme with the word “Mouse?” |
house |
|
Deep |
Does the word fit in the sentence, “The ___ was left out in the rain” |
cake |
Table 7.1 Summary of the experimental conditions in Craik and Tulving (1975)
Craik and Tulving expected that the “Deep Processing” condition would lead to better memory on a later surprise recall test. Indeed, this is what they found:
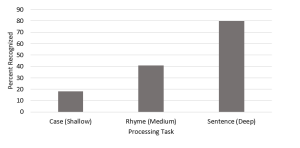
Figure 7.1. Results from Craik and Tulving (1975).
Later research has shown even better memory for even deeper processing—processing that involves making a judgment as to whether a word applies to you. For whatever reason—more elaborative encoding, a greater number of possible connections, or a simple egocentric bias—self-reference encoding clearly leads to durable memories (Brown, Keenan, & Potts, 1986; Klein & Kihlstrom, 1986).
This lab will look at levels of processing. You will be asked to make various judgments about words, and later your memory will be tested for these items.
At this time, complete the experiment Levels of Processing in COGLAB.
Instructions can be found in Lab 29 of the COGLAB website.
Questions for Lab 7
- What are the independent and dependent variables in this experiment?
2. Do your individual results show a levels of processing effect in general? What about the class data? Discuss your findings.
3. According to the reading, why should words for which you were asked to make “self-reference” judgments lead to better memory? Think of at least 3 possible explanations, and discuss how you could test one of these hypotheses.
4. One criticism of levels of processing explanations is that deeper processing tasks tend to take longer to do than shallow processing tasks. Discuss how you could test such an explanation.
5. Another criticism levels against the levels of processing hypothesis is that that it is fundamentally a “circular explanation.” What is meant by this? (You might want to consult your textbook to help you here.) Can depth of processing be measured independently of memory performance? Why or why not?
6. Will deeper processing tasks always lead to better memory? Can you think of conditions when a shallow level of processing might lead to better performance? Discuss.
7. Many students say they study differently for essay tests than they do for multiple choice tests. However, it might be that students are not studying differently for multiple choice tests, but just studying less (an Atkinson and Shiffrin explanation) or studying in a more shallow manner (a LOP explanation). How could you do about testing these explanations?
8. Suppose you slept in on Saturday, read a book, drove to your parents’ house, made your parents dinner, ate, drove home, and went to bed. On Monday, according to levels of processing theory, are you more likely to remember if you were stopped by a traffic light on your way to your parents’ house or what you had for dinner? Why?
Data Sheet for Lab 7
Name:
Levels of Processing
Individual Data
|
Condition/Task |
Accuracy |
|
Semantic/Encoding |
|
|
Semantic/Test |
|
|
|
|
|
Phonemic/Encoding |
|
|
Phonemic/Test |
|
|
|
|
|
Structural/Encoding |
|
|
Structural/Test |
|
|
|
|
|
Lure/Encoding |
|
|
Lure/Test |
|
Graphs for Lab 7
Individual Data
NAME:
Levels of Processing and Self-Reference
Group Data
NAME: