1 Lab 1: Research Methods in Cognition: How We Do What We Do
Introduction
Cognition, like many areas of psychology and neuroscience, is an empirical discipline. That is, the advances that are made in cognition are largely the result of research. Therefore, in order for you to gain an appreciation for cognitive psychology, you need to understand how research works.
This introductory lab will be a review for many of you. Most of these terms should sound familiar, especially if you have had statistics. We’ll be talking about concepts like independent variables, counterbalancing, data collection and analysis, etc. Please don’t be intimidated by these terms. Research is actually quite simple, but you have to learn to “speak the language.”
Cognitive psychologists employ several kinds of data collection techniques, each with different strengths and weaknesses. We’ll look at many of these techniques, but focus primarily on true experimental designs. These kinds of experiments are most typical of the ones we’ll survey throughout the course.
All of the research methods we will use involve variables. We divide these variables into two categories: dependent variables and independent variables. Dependent variables, which are seen in every kind of research design, are the things that we are interested in measuring. Another way of describing dependent variables is to say they are the data.1 No matter what kind of research we are doing, we will be measuring something: height, speed, accuracy, confidence, and so on. Every time we collect data from a subject we have measured a dependent variable.
Independent variables are things that the experimenter controls or manipulates. Often, when we are measuring something, we want to compare things. This is when we use an independent variable. Let’s say we have a new drug and think it might improve memory. We could simply give it to people and give them a memory test. But that won’t answer the question we really want answered–we need to make a comparison. So, perhaps we would get two groups of subjects. One of the groups would get the drug, and the other would not. Subjects receiving the drug form the experimental group, while subjects not receiving the drug form a control group. We would give subjects in both groups the same memory test, and see if the group taking the drug did better. In this case, the independent variable would be whether or not they got the drug. We control that, so that makes it an independent variable. The dependent variable would be their performance on the memory test.
We’ll look at several designs used in cognitive psychology. As you’ll notice, all of them use dependent variables. After all, we have to measure something! You’ll also notice, though, that not all of them use independent variables. There are times when we measure things even when we don’t manipulate things.
Introspection
Perhaps the earliest kind of research done in cognition was introspection. Developed by Wundt in the late 1800s, introspection involves “looking inward” and describing what is going on while some process is taking place. For example, say I asked you to imagine the house you lived in when you graduated from high school. Now, tell me if the door handle on the front door is on the left or the right side of the door. After that, I want you to count the number of windows in the first room you enter when you go into that house. If you are like most people, you can do that without too much difficulty.
Introspection takes that one step farther. Instead of just asking you the question, someone using introspection would be asked to report how they got the answer. We don’t really care how many windows were in that room. What we really want to know is how you arrived at your answer.
Thought Question
Try this exercise. How many windows are in the first room of your house? Before answering the question, make it a point to become aware of how you answered it. How easy was it to come up with the answer? How did you do it? Now that you are aware of how you did it, see if you can “count” the windows in the front room of a friend’s house or apartment. Is it easier to be aware of that?
Introspection was widely used around the turn of the century. Those in Wundt’s lab were the primary proponents, but other psychologists (like William James, the founder of American psychology) used it as well. In fact, the historical movement known as “structuralism” largely derived from this approach. Wundt’s followers were trying to identify the basic “structures” of mental activity, such as units of thought and reasoning.
As you probably remember from other psychology courses, introspection–the “study of the internal workings of the mind”–fell out of favor with psychologists after the turn of the century. A number of factors contributed to its demise. First, Wundt became increasingly dictatorial in authenticating introspective experiences. While other investigators tried to employ introspection, Wundt declared himself the final judge on the matter. If others found results that contradicted Wundt’s findings, Wundt might well dismiss their data as unreliable. Only Wundt’s immediate followers, operating under his close supervision, collected “reliable” introspective data (according to Wundt, that is).
In addition to this, it became clear that not all mental experiences could be studied using introspection. For example, try to decide if the following sentence is true or false: “A beagle is a dog.” Hopefully, you said that sentence was true. Now, introspect: how did you answer that question? If you are like most people, your answer would be something like this: “I don’t know how I knew it. I just knew it.” There will be quite a few times throughout the semester that introspection gives us the wrong answer. What we think we do isn’t always what we really do.
Finally, the rise of behaviorism put the final nail in the coffin of introspection. Behaviorists contended that the only thing appropriate for study was overt behavior. Trying to infer what was going on in the mind was considered fruitless, since activities taking place in the “black box” could never be empirically verified. As the power of Watson and Skinner rose, introspection was largely abandoned.
Thought Question
Try this demonstration. Assume I give you a series of numbers to remember, like this:
5-2-8-1-3
Now, I am going to ask you if a certain number was in the set I asked you to remember. All I want you to do is tell me if the number I give you was in that original set. Do you have the set in mind? (it was 5-2-8-1-3, in case you forgot). Here’s the number: 2
Introspect for a minute. Once you found the item you were looking for (“2” was in the set I gave you to remember) did you keep looking at the rest of the numbers? In other words, did you quit the search once you found the “2” in the original set, or did you finish looking at the rest of the set, even after you found what you were looking for? The answer may surprise you, and we’ll come back to that in Lab 5.
Strengths and Weaknesses of the Introspective Approach
Introspection is a valuable technique for several reasons. First of all, good introspection can lead to powerful insights. For example, James, through introspection, arrived at the conclusion that there were two memory stores, what we now call short- and long-term memory. Second, it is a very efficient technique. All you need to conduct introspection is a place where you can concentrate. Finally, introspection allows the processes underlying complex cognitive activity to be broken down. Recently, Ericsson and Simon (Ericsson & Simon, 1980) adapted the introspective technique for use in problem solving activities. They use what they call “think-aloud protocols.” They asked their subjects to think out loud as they were solving a given task, such as trouble-shooting an electrical circuit. Ericsson and Simon found that they could often discover how the problem solvers worked by analyzing these protocols.
Thought Question
You can demonstrate this think-aloud protocol for yourself. Try to name as many states as you can, and while you are doing it, try to say everything that comes into your mind. A few states, like Texas, may just “pop into your mind.” Before long, though, you’ll likely find yourself using some kinds of strategies to help. What kinds of strategies did you use? Did you find some more successful than others?
As we have seen, not all cognitive tasks can be assessed using introspection. A number of these tasks could be considered “automatic.” Automatic tasks are defined as tasks that occur without awareness on the part of the subject, require no cognitive resources, and occur without intention. You cannot “turn them off.” A good example of an automatic process is word recognition in skilled readers. Try to look at this word, and see only the letters of this word:
HAPPY
You almost certainly could not do it. You can’t help but read the word.
By definition, automatic processes are those for which we cannot be introspectively aware. If I were to ask you to introspect on how you read the word “happy,” you could not do it. We’ll examine automatic processing in Lab 2, and again in Lab 3, which deals with the Stroop effect.
The behaviorists are right at some level–there is no way for a researcher to know if subjects are actually thinking in the way they claim they are. For example, one of the previous questions asked you to determine how many windows were in your house. You might report that you did this by mentally imagining your house, and then counting the windows in your image. Is this what you really did? Though it seems likely, there’s no way we can be certain.2
Case Studies
Another technique used in research utilizes individual subjects who are exceptional in some way. Analyses of these subjects are called case studies. Often by looking at exceptional individuals, we can understand how “regular” individuals work.
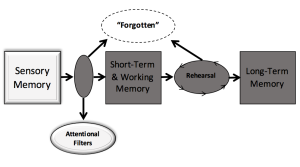
You are certainly familiar with case studies. Sigmund Freud developed much of his theoretical work from a relatively small number of detailed case studies. In cognitive psychology, we have gained a great deal of insight into memory function by looking at exceptional individuals. Perhaps the most famous individual in all of cognitive psychology is a man known only by his initials: “H. M.” H. M. was diagnosed in the early 1950s as suffering from a very severe form of epilepsy. As a last resort, he was treated by destroying those parts of his brain that triggered the seizures (in H. M.’s case, the hippocampus and the amygdala). When H. M. recovered from the surgery, his epilepsy was almost completely eradicated. Unfortunately, the surgery had a very severe complication: it left H. M. unable to form any new long-term memories. Every time H. M. encounters a former acquaintance, it seems to him to be their first meeting. His memory for events prior to the surgery is intact, and his short-term memory is also fine. However, he cannot form new long-term memories. Every time he is distracted, and the contents of his short-term memory disrupted, he forgets what he was just talking about. He can work the same crossword puzzle time and time again, with no recollection of having seen it before. In short, H. M. is perhaps the strongest evidence psychologists have for the distinction between short- and long-term memory, and we’ll study this in Lab 7. Hilts (Hilts, 1995) provides a fascinating biography of H. M. , and discusses the challenges brought on him his profound and irreversible amnesia.
Strengths and Weaknesses of the Case Study Approach
As you will see, psychologists often find out a great deal about how normal cognition takes place by observing abnormal cases. H. M. is a great example. We learn how memory functions normally by finding individuals in which the normal function of memory has been disrupted. Because H. M.’s short-term memory works in the absence of a normally-functioning long-term memory, we have to assume that the two are separate entities.
Case studies allow us to observe things that we could not ethically create. It would be impossible, for example, to take a human being and perform a lobotomy like the one H. M. received, just to observe changes in memory.
However, the use of case studies has some considerable drawbacks. One of the most serious involves a bias in the selection of subjects. Freud’s theories of personality were derived in part from his experience with his patients. He utilized case studies extensively (you’ll remember Anna O., for example). The individuals that Freud saw in his practice, though, were hardly “typical.” They were for the most part well-educated, wealthy, female, sexually-repressed Victorians. While Freud gained some real insights into their personality structure, his analyses were not applicable to all people.
Another serious drawback in using case studies is the lack of a control group for comparison. It’s very tempting to conclude that H. M.’s memory impairment was the result of his temporal lobe damage. We really can’t say that, though, at least not with absolute certainty. H. M. was also an epileptic, which introduces the possibility that his memory impairment could’ve been caused by twenty years of seizures. It might also have resulted from the anesthesia given prior to his operation, or a mistake by the doctor during surgery. Any of a number of other factors might come into play. We’ll come back to the topic of control groups later in the chapter.
Observation
Another powerful research tool involves watching organisms (humans and non-humans) behave in their natural environment, a technique called observation. Sometimes when we try to study something scientifically, we end up controlling things too vigorously, such that we influence the behavior in ways we did not intend by creating an unnatural environment. If we want to see how monkeys behave in groups, for example, a good way to do that would be to silently observe them in the jungle. If we want to judge how racially prejudiced people are, we could observe how likely they are to take a seat in a crowded bus next to a non-Anglo.
You are probably familiar with the work of Jane Goodall. Goodall is an anthropologist who studies the behavior of chimps in the wild. Her painstaking work requires that she spend months, even years, in the wild with the chimps. She does her best to remain unobtrusive, and eventually the chimps act as if she wasn’t even there. She has used observational techniques to study aggressive behavior, sexual behavior, parenting, etc.
Strengths and Weaknesses of the Observational Approach
As the work of Goodall demonstrates, much can be gained using the observational technique. Because our subjects do not know they are being observed, they are much more likely to behave “normally.” We can gain insights into real-world behavior that we otherwise could not.
Despite these real advantages, observation has shortcomings as well. First of all, though we often provide a very good description of naturalistic behavior, we cannot provide an explanation of it. We may know that in a kindergarten classroom, Billy always wins the fight over the Legos. We might even be able to go into considerable detail in our description. But we won’t know why he always wins. He might have won because he’s the largest, or because he’s the most aggressive. He might have won because nobody else likes Legos. He might have won because he’s male. We just don’t know, based solely on observation. Because we can’t control certain factors, we can’t draw conclusions on what caused the behavior.
Correlational Techniques
Sometimes researchers are interested in looking for relationships between variables. Let’s say we give you a speeded test, like the SAT. We can measure several things when we give you that test. First, we can measure your accuracy. What proportion of the questions did you answer correctly? We can also measure your speed on the test: how many questions did you get through? From taking these kinds of tests, you might suspect that there is a relationship between speed and accuracy. Perhaps you hypothesize that as subjects work more quickly, their accuracy on the test goes down.3
The way to look at this relationship is to use a correlation. A correlation is a way of seeing how things relate to one another numerically. These correlations are often displayed using what is called a scatter plot. On a scatter plot, each dot represents an observation. Let’s look at a hypothetical scatter plot for the experiment we described above, looking at the relationship between speed and accuracy on the SAT. The scatter plot is displayed in Figure 1.1
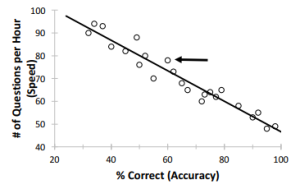
Figure 1.1 Hypothetical scatter plot between percent correct and rate of question answering.
Each dot on the graph represents the performance of one person. Each person has a score on two variables: the percent correct on the test (the measure of accuracy) and the number of questions they answered per hour (the measure of speed). The point on the graph identified by the arrow is a person who got 60% correct on the test (you can tell that by reading straight down from the point to the x-axis) while answering 78 questions per hour (you can tell that by reading straight across from the point to the y-axis). As you can clearly see from the graph, there is a strong negative relationship between the two variables. As one increases, the other decreases. This would be an example of a negative correlation.
Let’s take another example, the relationship between number of cigarettes smoked in a day and the likelihood of developing lung cancer. (Again, I have made these numbers up.) A scatter plot might look something like Figure 1.2. This relationship provides an example of a positive correlation: as one variable goes up, so does the other.
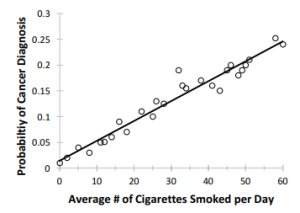
Figure 1.2 Hypothetical scatter plot between number of cigarettes smoked and cancer rates.
Strengths and Weaknesses of the Correlational Approach
Correlations are designed to show relationships between variables. They do this very well. Many researchers use correlations to see if there are relationships between diet and health, exercise and weight, and so on. Correlational research is often fairly cheap, and provides a good estimate of the strength of the relationship of interest.
It is tempting in this case to take the correlation between smoking and cancer as evidence that smoking causes cancer. This is where correlations fall short, though. Correlation cannot show causation. Just because two things are correlated does not mean one is causing the other. It certainly seems likely that smoking causes cancer, and we know from other data that smoking does cause cancer. But from studies like these, using only correlational data, we cannot infer causation.
Another example might make this even clearer. As you are probably aware, there is a modest correlation between SAT scores and freshman GPAs. Which is causing which? As you likely surmised, neither is causing the other. Probably, both are being caused by a third variable, such as level of education or intelligence. Just knowing that two things are correlated does not mean we can tell which is causing the other.4
Experimental Designs
In case you haven’t noticed, each of the designs described above lack independent variables. In each case we are measuring things, so we have dependent variables. But none of the designs described above involve experimental manipulation. As a result, we cannot determine cause and effect. True experiments, though, do allow us to decide which variable is causing the other.
Experiments rely heavily on control. We want some things to vary between groups (these are our independent variables). But we want everything else to be as consistent as possible. Say we are looking at the effects of a new drug on aggression. We’ll treat the drug as an independent variable (one group gets the drug, the other does not). Especially since we are looking at aggression, we would want to attempt to place an equal number of males and females in each treatment group. Otherwise, we might end up with 80% males in one group and 20% males in the other. If we found differences between the groups, we wouldn’t know if they were due to our drug treatment or to the differences in gender.
Experiments can be performed in several ways. Again, take the example of our drug and aggression. We’ll test for aggression by putting subjects in a room with a coke machine that eats quarters. We’ll tell them that they are to wait here for the experimenter to return, give them $1.25 for the coke machine, and tell them to help themselves to a drink while they wait. Of course, we’ve rigged the machine up so that it will take their money but give them nothing in return. We’ll count the number of times they hit the machine, and use that as a test of aggression.5
If we have many subjects (let’s say for the sake of argument that we have 200), we could assign half to one of our treatment conditions (the drug condition) and the other half to the other condition (the no-drug condition). One hundred subjects in both conditions is enough for us to split them like this. Assigning subjects to experimental conditions like this is an example of a between-subjects design. All of my treatment effects are between subjects. A given subject is either in one condition or the other–not both.
The experiment could be performed another way. We could take all of the subjects and put them in both conditions, one after another. That is, they could take the drug once, we could measure their aggression, and then we could ask them to return the next day (to let the drug wear off). The next day when they return, we will test them under the no-drug conditions. When subjects participate in all the conditions in an experiment, this is called a within-subjects design. In this case, we compare the subject to himself instead of to the other subjects. Within-subjects designs are very useful when the number of subjects is small. As a result, we’ll be using within-subjects procedures whenever possible this semester.
Thought Question. What kinds of advantages and disadvantages do you think between- and within-subjects designs have? When would you choose one, and when would you choose the other?
The within-subjects experiment we just described has some serious problems. Most seriously, we had all of our subjects first tested under the drug condition, and then in the no-drug condition. Many things might be causing differences besides our drug. For example, the second time subjects are put in the room with the Coke machine, they may be reluctant to even put their money in. Or, they may get even more frustrated the second time because they’ve now lost money twice. Or, they may get less angry the second time because they expected the machine to be broken. Perhaps they are growing suspicious of our little deception, and are now behaving in ways they wouldn’t normally behave. There might be dozens of reasons to expect differences, in addition to the drug. Variables that aren’t controlled for are often called nuisance variables.
These problems can be dealt with, though. For our purposes, one of the easiest ways to control them is to use what is called counterbalancing. Counterbalancing involves switching the order of presentation from one subject to the next in order to eliminate problems of repeated testing. In the example above, we could counterbalance by having half the subjects participate in the drug condition first, and the other half in the no-drug condition first. The next day, they would switch. Any effects of order would cancel each other out, hence the name “counterbalance.”
Counterbalancing is critically important when using repeated measures (another name for within-subject) designs. Several things can often happen with repeated testing. In many instances, subjects tend to get better at whatever task they are doing. These are called practice effects. Several of the experiments we’ll do this semester are difficult. You’ll find them to be much easier with a little practice. Let’s say we are having you memorize 4 lists (A, B, C, & D) of 15 words, as they are being presented on the screen. The first time, you find that they go by too quickly, and you might do poorly. As you get better prepared, you do better on the second list, and so on. Performance is always best on the 4th list. But is this due to the practice or something else? So, in order to rule out practice effects, we’ll have to make sure that some subjects get list A first, some get list B first, etc. That way, if we find performance is best for list D, we know it can’t be due to practice effects: some subjects had list D first, some had it second, some third, and some fourth.
There is another reason to counterbalance: fatigue. Though our experiments are all fairly short, some require serious concentration, and you might find yourself fatiguing near the end. This might make performance worse on the last parts of the experiment. If we make sure that not everybody does the same thing first or last–that is, if we carefully counterbalance–we can overcome problems of practice or fatigue.
With a few important exceptions, we’ll be using two main classes of dependent variables this semester: accuracy and speed. We often want to know how accurate you were on a given test, so we’ll measure things like number of words recalled, proportion of items recognized, and proportion of correct decisions. All of these are measures of accuracy.
There will be some instances, however, when accuracy is not an informative dependent variable to measure. For example, in Lab 8 we’ll be asking subjects to look at a string of letters and determine if those letters make up a word. For example, GRASS is a word, and you would respond positively. GRUSS is not a word, and you would respond negatively. In cases like this, your accuracy will be virtually perfect. So, instead of measuring your accuracy, we’ll measure your reaction time.
It is vitally important that you understand the concepts of independent and dependent variables, operational definitions, control groups, and counterbalancing. You must also be aware of the differences between within-subjects and between-subjects designs. We’re going to use these terms in every lab we perform. If you still feel uncomfortable about these terms, ask the lab instructor.
Questions for Lab 1
For questions 1-3, answer:
a. what kind of research design is being used? (i. e., case study, introspection, etc.)
b. what is the independent variable? (if any)
c. what is the dependent variable? (if any)
d. what is the experimenter trying to measure?
e. what was the operational definition used by the experimenter?
f. what are the strengths and weaknesses of the design that is being used?
g. what are the strengths and weaknesses of the operational definition?
1. A psychologist is interested in looking at the relationship between type of instruction and learning to solve algebra word problems. She knows one junior high school teaches students to solve using Method A. She knows another junior high school uses Method B. At the end of the term she gives both groups of students the same exam, and compares their performance.
2. A psychologist is concerned that children who drink caffeine at lunch have more attention problems in school during the afternoon. To study this, she watches students at lunch, and notes who has a caffeinated drink and who does not. After lunch, she sits in the back of the classroom and records how many times each child gets up from his or her seat.
3. In order to get an estimate of how race influences people’s reaction, two psychologists set up a scenario in a mall. They pick a narrow hallway in the mall, and stage a conversation between two people. The hallway is narrow enough that if someone walking past them wants to get by, that person will either have to squeeze behind them, or walk between them, interrupting the conversation. They believe that people will be more likely to interrupt if one of the pair is black. They have several pairs of people. In some pairs, both are white. In other pairs, both are black. In the remainder, one is white and the other black. They count how many times passers-by walk through and not around .6
4. A researcher wants to study how sleep influences college students’ test performance. They randomly assign individuals to sleep either 3, 6, or 9 hours per night for one week. At the end of the week, all subjects are given a vocabulary test from their introductory psychology class, and the researcher compares the results.
5. Come up with three operational definitions (each) for
a. attraction
b. anger
c. happiness
d. compliance
e. memory