8 Lab 8. Semantic Memory and Lexical Decisions: Is “Mross” a Word?
COGLAB Exercise 42
Semantic vs. Episodic Memory
One question that has plagued psychologists for over 100 years has been whether memory is a unitary construct, or whether there is more than one “kind” of memory system. We’ve already looked briefly at the differences between short- and long-term memory, but recently researchers have been asking whether or not there is more than one kind of long-term memory. Perhaps the most influential researcher in this area has been Endel Tulving. Tulving (1972; 1985) has distinguished between semantic memory and episodic memory.15 Both are considered to be long-term memories, but they differ in a number of respects. Episodic memories are your personal memories, where you are an active agent in that memory. A first date with a new significant other, the time when your pants ripped at summer camp, and the day your younger sibling came home from the hospital, would all be examples of episodic memories. They are often emotional and personal, and they are very likely to be unique to you.
Semantic memories, by contrast, are depersonalized “facts.” Your semantic memory is like your encyclopedia of knowledge. You know that the “mean” and the “average” are the same thing. You know that Sigmund Freud was a famous personality theorist. You know that Elvis is dead (reports from Saginaw, Michigan notwithstanding). These are all generic facts that most people living in a common culture know.
This lab will focus on semantic memory, for several reasons. Our episodic memories are likely to be highly individualistic. For instance, your memory for your first class in college is certainly very different from mine. For that very reason, it would be difficult to effectively investigate these memories. Researchers can’t know if your memory is accurate, since they weren’t present when it was originally formed. With a few exceptions, most studies of episodic memory have subjects learn some new information in the lab, and then test them on that recently learned information.16
Our semantic memories are likely to be somewhat similar, though. Assuming we all have roughly similar cultural and educational backgrounds, you are likely to know the same kinds of things I know. We all know that a robin is a kind of a bird, that puppies grow up to be dogs, and that George Washington was the first president of the United States. There are some differences, of course–a baseball fan may know who Honus Wagner was, and why his baseball card is worth so much–simply because they know a lot about baseball.17 You may know a number of things about music or art that the baseball fan doesn’t know. Personal hobbies and interests aside, though, there is a great deal of knowledge that we all share.
Discussion of Semantic Memory Models
Interestingly, the first models of semantic memory were designed not by psychologists, but by computer scientists. These scientists were interested in an approach to cognition called artificial intelligence. The goal of artificial intelligence (AI) is to build computer models that can perform complex cognitive tasks. Some of these programs, like most of the chess programs you can buy for your computer, are designed simply to perform the tasks as efficiently as they can, regardless of the methods used. Other programs are designed not necessarily to perform faster or more efficiently, but to mimic the way humans would go about the task. These are called cognitive simulations.
To illustrate the difference between the two approaches, consider the recent performance of IBM’s “Deep Blue” chess-playing computer. In April, 1997, Deep Blue became the first computer to beat a grand master (Kasparov). To do this, Deep Blue considered billions of possibilities before selecting each move. Conversely, human players rarely study more than a dozen moves before picking one. Kasparov probably would’ve considered this many moves had he been able, but obviously human beings are incapable of such extensive mental thought. So, while we now have a computer capable of beating a grand master, such programs tell us very little about how humans play chess18.
Cognitive simulations are built to mimic human performance, errors and all. Some simulations are built to model human experts, like physicians. These simulations can aid in diagnosis, but because they are designed to behave like humans, they are capable of making the same errors that human doctors might make.
The first models of semantic memory were kind of a blend of the two approaches. As computers became more powerful (and more prevalent), researchers began looking for ways to bestow computers with knowledge. In present day terms, they were interested in building a semantic memory for computers.
Collins & Quillian’s Hierarchical Network Model
A young computer scientist named Ross Quillian was trying to build a computer program that could understand language. He realized early on that a “dictionary” approach to this task would not work. This dictionary approach was tried in the 1950s in the area of language translation. Early investigators thought that material could be translated from one language to another simply by looking up the word in a computer “dictionary” and writing down its translated equivalent. Though this sounds promising, it was an unmitigated disaster. One story, probably apocryphal, is that the sentence: “The spirit is willing but the flesh is weak,” was translated from English to Russian, then back to English. The twice-translated results: “The vodka is fine but the meat is rotten.”
Quillian began the daunting task of giving a computer the knowledge it would need to understand things like a newspaper or textbook. How would he do this? Quillian not only had to have the information stored, but he had to organize that information so that it could be quickly and accurately accessed. He also realized that space would be a problem. He wanted his information to be stored efficiently as well. As an analogy, one could find an answer to a question about Bach by starting with the first book in the library and reading through all the books until the desired information was found. While this would work (eventually), it is not at all efficient. The person would be better advised to consult with the card catalog before searching. In order for such a system to work efficiently, the information in the library must be stored in an organized manner. The same would be true of a computer model.
Quillian’s approach was based on a few assumptions that seemed reasonable. As you’ll see, the information is going to be stored in a hierarchical fashion, in such a way to allow for inferencing. Quillian (1968) was somewhat successful in a number of respects, and called the final model “Teachable Language Comprehender,” or TLC. When his project was completed, Alan Collins, a cognitive psychologist, was struck by how well the model did some things, and was also intrigued by the possibility that this might be how human memories are stored. Thus, Collins and Quillian fashioned a model of semantic memory based on Quillian’s TLC.
The model makes some strong predictions about how information is stored and retrieved. As such, it provides a good, testable model. Since we are most interested in the structure, and not the content, of semantic memory, the dependent variable to be examined is retrieval speed, or reaction time. Collins and Quillian presented their subjects with very simple sentences, like “a robin is a bird,” and had subjects press one button if the sentence was true, and another if the sentence was false. The rate at which subjects could respond to such sentences was thought to give some indication of how semantic memories are organized.
The basic structure of the Collins and Quillian model is illustrated in Figure 8.1. The model proposes that concepts are stored in what are called “nodes.” These nodes are connected to one another by ties called “links.” By arranging the nodes and links together we can essentially represent a network of concepts.
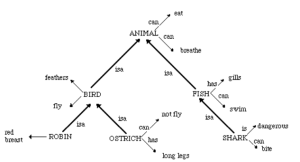
Figure 8.1 Example of Collins and Quillian’s Hierarchical Network Model
The links not only indicate that things are related, but also how they are related. The concepts “bird” and “wings” are related by the fact that a bird has wings. However, “animal” and “eat” are connected by the link that stores the fact that an animal can eat. There are special links in the hierarchy called “isa” links, indicating category membership. “Robin” and “Bird” are related in a special way–a robin is a bird. “ISA” links were called category links by Collins and Quillian, while the other links–”can,” “is,” “has,” etc.–were called property links. There will be some important differences between these when it comes to reaction times.
Notice several things about the model. First, it is arranged hierarchically, so that some information is at the “top” and some at the “bottom.” The information at higher levels in the hierarchy is more general, while the information at the bottom is more specific. Second, notice how the storage of information allows us to make inferences. If you are asked a question like, “Can an oxynotel fly?” and you have just learned that an “oxynotel” is a bird, you can traverse the “isa” link to answer the question. Your reasoning might be something like, “I don’t really know, but I do know that an oxynotel is a bird, and I know birds can fly, so I will infer that yes, the oxynotel can fly.”
Finally, notice that all the information about nodes is not directly represented within that node. It’s true that a robin can fly, and that a shark can eat, but those specific relationships are not stored. Not only can robins fly, but almost all birds can fly. To make things more efficient, Collins and Quillian stored information at its most general level only. This is called the principle of cognitive economy. If we stored everything we knew about birds in general at the robin node also, there would be a great deal of redundancy. We’d have to store that robins can fly, that eagles can fly, that sparrows can fly, and so on. Cognitive economy allows us to store general information more efficiently. So what about exceptions to the rules, like the fact that ostriches, despite being birds, cannot fly? Quite simple–exceptions are stored directly with the concepts. You can see this illustrated on the “Ostrich” node in Figure 8.1.
The fact that the memory system is arranged in this way means that most of our question answering in this task will have to be done by some kind of inferencing mechanism. When asked “can a robin eat?” we’ll have to traverse several “isa” links until we can verify the answers.
Now that we have the information organized efficiently and economically, we turn our attention to how that information is searched. Collins and Quillian assumed that the search process starts at the subject node first encountered when reading the sentence. Therefore, if the sentence is “A robin can breathe,” the search will begin at the “Robin” node19. Once at the starting node, the model assumes that the sentence is verified by first looking at the concepts stored directly with the “robin” node. If a match is found, then the search process stops, and the “YES” answer is fairly rapid. If the match is not found, then the search process moves to the next highest level to see if a match can be made there, and so on. If a match is found at any stage, the search process terminates.
The notion that a search begins at one node and spreads to others is called spreading activation. When a concept is read, it becomes “active.” As time passes and the search continues, that activation spreads to other nodes like ripples in a pond. The spread of that activation takes time, which is reflected by increases in reaction time. The concept of spreading activation is one of the most influential constructs in many memory models even today, more than 20 years later.
The model makes the prediction that the greater the number of levels searched, the greater will be the time to respond to that sentence. A property sentence like “A shark can bite” is considered to be a P0 statement, since it is a property statement that can be verified by moving up zero levels. “A shark can swim” would be a P1 statement, since 1 additional level has to be searched. “A shark can eat” is a P2 statement, since 2 additional levels have to be searched.
A similar prediction can be made for category statements. “A shark is a shark” would be a C0 statement, “A shark is a fish” would be a C2 statement, and “A shark is an animal” would be a C3 statement. Therefore, C0 statements should be verified the most quickly, followed by C2, then C3.
Collins and Quillian’s model was designed to verify TRUE sentences only. They concluded, when studying falsification, that the falsity of a sentence could be determined in so many ways that it would not be possible to predict exactly how a given false sentence would be answered. “A shark plays basketball” could be falsified by realizing that sharks don’t have arms, that basketballs float, that there aren’t basketball courts in the ocean, etc.
The first series of studies seemed to indicate support for the hierarchical network model. The results are shown in Figure 8.2. As expected, the greater the number of levels traversed, the greater the time needed to determine the truth of the sentence. For both category and property statements, the slope of the functions was about 75 msec. That is, it took about 75/1000 additional seconds to traverse to a higher level.
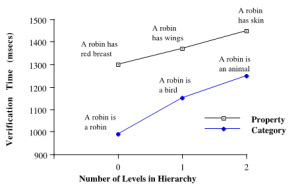
Figure 8.2. Mean verification time on sentences as a function of the number of levels traversed.
Discussion of Semantic Memory Research
Over 20 years of semantic memory research has uncovered neither the exact structure of semantic memory, nor the processes involved. We have learned a great deal, but we still cannot conclude anything definitively.
The line of investigation initiated by Collins and Quillian served to help draw attention to the structure of semantic memory. Certainly, the huge storehouse of information in our semantic memory must be organized in some way. We have learned–and are continuing to learn–what some of those organizational principles are.
For present purposes, one of the most important results of the work on semantic memory was the notion of spreading activation. The idea that knowledge is stored in memory in some structured way is important. Equally important is the notion that how “close” things are psychologically can be inferred from how long it takes you to respond to certain questions. Since your affirmative response came more quickly to “A robin is a bird,” than to “A robin is an animal,” we can infer that “robin” and “bird” are related, and that they’re stored more closely together than are “robin” and “animal.”
Lexical Decisions as a Way of Measuring “Closeness”
Another way to see if concepts are related is to see what happens when they are presented together. If subjects react more quickly or more accurately when items are presented close together in time, we can assume that they are somehow related.
Lexical decision tasks couldn’t be simpler. Subjects are presented a string of letters and asked to determine if that string forms a word. If subjects see: DOCTOR, they should say “yes.” If they see: HIPTED, they should say “no.”
In general it takes about 600 msec to respond positively, and slightly longer than that to respond negatively. Sometimes, though, we can influence how quickly subjects respond by presenting specific combinations of words. Consider the following examples. Each of the words would be presented one at a time, on the computer screen. The DECISION column displays the correct response, while the TIME column displays how long the subject would typically take to respond:
|
WORD |
DECISION |
TIME (msec) |
|
GRASS |
Yes |
600 |
|
MROSS |
No |
650 |
|
BUTTER |
Yes |
600 |
|
NURSE |
Yes |
600 |
Next, take a very similar example, but notice how the third word and fourth time change:
|
WORD |
DECISION |
TIME (msec) |
|
GRASS |
Yes |
600 |
|
MROSS |
No |
650 |
|
DOCTOR |
Yes |
600 |
|
NURSE |
Yes |
550 |
Notice that the response time for the word NURSE is now about 50 msec faster. Why? Many theorists rely on the concept of spreading activation to explain this finding. The word we are interested in, NURSE, is commonly associated with the word DOCTOR. Thus, we think they are psychologically “close.” In order to make a decision for each word, we assume that you have to search your memory and activate the appropriate concept, or “node.” When you access the node for DOCTOR, the concept becomes activated. As the name “spreading activation” implies, some of the activation associated with DOCTOR spreads to related nodes, such as HOSPITAL, NURSE, and BMW. When you later go to access the node for NURSE (when it appears on the screen, and you have to make a lexical decision about it), the node is already somewhat activated. The activation from DOCTOR that has spread to NURSE means that NURSE can be activated somewhat more easily. A simple semantic network might look like Figure 8.3.
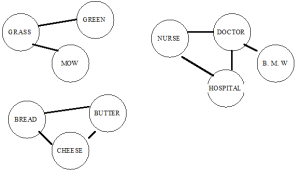
Figure 8.3. A typical semantic network
Notice that things that are related (like BREAD and BUTTER) have links connecting them, while things that are not related (like GRASS and DOCTOR) do not have links connecting them. After we read the first word, the GRASS node would become active, and some of that activation would spread to related nodes. It would look something like Figure 8.4 (the more highly activated nodes are shaded more darkly).
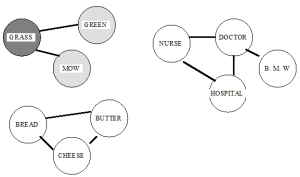
Figure 8.4. A semantic network after having the GRASS node activated. Notice how some of the activation has spread to related nodes.
Activation from a node fades very quickly, so not long after GRASS (and the related nodes) becomes activated, it loses its activation. When the third word, DOCTOR, is read, the network would look like Figure 8.5. When the word NURSE is read, and the network tries to activate it, it won’t take as long to do it. The NURSE node is already somewhat activated.
This powerful technique is called “priming,” from the analogy of priming a pump. (Remember we talked about “negative priming” in Lab 3). The first word in the related pair (the word DOCTOR in the DOCTOR-NURSE pair) is called the prime word, and the second word, NURSE, is called the target word. Though we’ll measure how fast you respond to all words, we’re really only interested in your response to the target word. The question of interest: is your response to the target word faster if the prime word is related? In other words, will you respond more quickly to NURSE if the prime is DOCTOR instead of BUTTER?
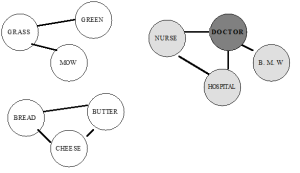
Figure 8.5. A semantic network after the word DOCTOR has been read.
There are two main ways of performing this kind of research. One of them involves the presentation of single words, with a response made to each word. Immediately before giving you the target word, we present the prime. A second way of doing lexical decision research involves presenting both the target and the prime word at the same time. The subject is to press one key if both of the letter strings are words, and press a second key if either (or both) of the letter strings are not words. This second approach is the way our experiment is set up.
This very simple paradigm is a powerful tool for studying the structure of semantic memory. We can also use it to study unconscious perception: does presenting a prime at a level beneath recognition (unconsciously) facilitate responses to targets of which we are conscious? Some studies of attention have used this technique.
Thought Question
Would you expect unconscious priming to take place? Why or why not?
At this time, complete the experiment Lexical Decision in COGLAB. Instructions can be found in Lab 42 of the COGLAB website.
Questions for Lab 8
1
. Compare your individual data and the class data to the results obtained by Meyer and Schvanevelt (1974). Do our results agree with theirs?
2. Look at the accuracy rates. Were there any differences in accuracy? Are the error rates so high as to call into question our results?
3. Compare both the error rates and the reaction times, looking for a speed-accuracy tradeoff. What pattern would you expect if there were such a tradeoff? What did we actually get? Discuss both your individual data and the group data.
4. Earlier, we said that reaction time was used as the primary dependent variable here because accuracy was very high in all conditions. There are ways to use accuracy measures instead of reaction time. How might that be accomplished? Hint: think about how you could force the subjects to make more errors so that accuracy changes.
5. How do you think the results would have differed if we asked subjects to make lexical decisions to single words, rather than word pairs? Are there some advantages to the single-word approach? Any disadvantages?
6. How do you think the results would have differed if we had presented the words auditorially instead of visually? What do you think would happen if we presented the prime word auditorially and the target word visually? Explain your reasoning. Hint: think about whether the decisions would be more or less difficult (accuracy) or faster/slower (reaction time).
7. You enjoy watching game shows and one of your favorites is Jeopardy. Jeopardy is a quiz show in which contestants answer questions from a set of identified categories. When you watch the show, you notice that if you did not see the question category before the question was asked you are never able to come up with the correct answer before the question timer runs out. Using what you have learned from this demonstration, why might this be the case?
Data Sheet for Lab 8
Lexical Decision
Name:
Report Mean Percent Reaction time (in ms)
|
|
|||
|
|
Word + Related Word |
Word + Unrelated Word |
Nonwords |
|
Reaction Time
|
|
|
|
|
|
|
|
|
Graphs for Lab 8
Lexical Decisions and Semantic Priming
(Reaction Time Only)
Individual Data
NAME:
Lexical Decisions and Semantic Priming
(Reaction Time Only)
Group Data

Turn this graph in along with your lab
NAME: